

Predicting House Prices in the Massachusetts area using Linear Regression, Support Vector Regression and Random Forest Regression
Introduction
For this project, I scraped housing data from Zillow websites and used features such as the price, the size of a house in feet, number of beds and baths to predict the price of the house. The goal of this project is to understand multiple regression algorithms and see how they function on a real-world problem.
The Machine Learning Process
The data process included :
Data collection and cleaning: I scraped the data from Zillow websites for the particular cities in Massachusetts and did some data cleaning by removing rows with empty fields and those without bedrooms and baths in their columns. The data was log transformed to ensure that there were perfectly skewed.
Machine Learning Algorithm: The clean data was then passed into multiple machine learning algorithms such as linear regression, support vector regressor and random forest regressor to predict the price of the houses.
Evaluate Machine Learning Algorithms: The myriad algorithms were evaluated to see how they performed. Spoiler alert: Random forest regression did the best amongst the three while linear regression performed worse.
Display Result: The predictor was then sent to a flask app where the users can try multiple inputs to the models to see how the price of the algorithm changes.

Machine Learning Introductions
Linear Regression
Linear regression is a supervised learning algorithm that fits a line through the data to predict a continuous variable. The algorithm tries to minimize the residuals (the difference between the predicted and actual value) as it calculates its prediction,
Support Vector Regression
Support Vector regression is a supervised learning algorithm that tries to fit the error rate within a threshold boundary line. Usually the boundaries are the innermost threshold that supports the vectors. A threshold is chosen that allows for misclassification to ensure the data is transformed to its right plane.

Random Forest Regression
Random forest regression is a supervised learning algorithm that utilizes a combination of decision trees to produce a continuous output. Usually the combination of models together is called an ensemble model.Random forest uses a Bagging ensemble method (Bootstrapping and Aggregation) to come up with it model output. Bootstrapping is row sampling with replacement and takes the output and then Aggregates the results using a voting classifier to get the output.

Evaluation Metric
The model was evaluated using the R squared metric which basically finds the goodness of fit of the model. There is a generic formula for calculating r squared that can be found online.
Here are the result of the models.
Linear regression: 65.7%
Support Vector Regressor: 71.2%
Random Forest Regressor: 80.4%
Project Demo
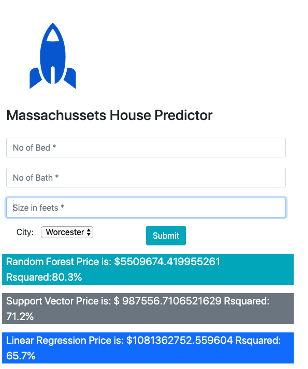
A screenshot of the actual website of the project can be found below. Users can enter their inputs and get results from the different models in the application. Something to note is that we are predicting per city and some cities have more observations than others.
Conclusion and Future Works
Prediction of house prices in the Massachusetts area has been achieved. I need to collect more data for better prediction and develop the flask web ui some more.
Link to the project can be found here on github with my contact.